


Articles . Simplistic Marching Cubes Optimization
The marching cubes algorithm is a well-known algorithm in the field of computer graphics that provides a rather straight-forward way of generating polygon meshes from voxel data. Naive implementations that follow the basic description of the algorithm in question are not too hard to find, yet many of these example implementations suffer from the fact that they are generating non-unified / non-indexed triangle meshes, besides evaluating voxel density functions up to eight times in exactly the same spot. This article addresses both of these issues providing rather simple, yet fast and efficient solutions yielding perfect results.
Premises
The basic naive implementation to be optimized throughout this article is assumed to be of the form:
static const D3DXVECTOR3 relativeCornerPositions[8] = {
{0,0,1}, {1,0,1}, {1,0,0}, {0,0,0},
{0,1,1}, {1,1,1}, {1,1,0}, {0,1,0} };D3DXVECTOR3 vertices[MAX_VERTICES];
unsigned int indices[MAX_INDICES];
int vertexCount = 0;
int indexCount = 0;
// Loop over grid cells
for (int x = 0; x < stepsX; ++x)
for (int y = 0; y < stepsY; ++y)
for (int z = 0; z < stepsZ; ++z)
{
int nTriangles = 0;
Triangle triangles[5];
Cell cell;
// Loop over 8 cell corners
for (int i = 0; i < 8; ++i)
{
// Compute cell corner position
D3DXVECTOR3 &cellCornerPos = cell.p[ i ];
cellCornerPos = D3DXVECTOR3((float)x, (float)y, (float)z) + relativeCornerPositions[ i ];
// Compute iso value
cell.val[ i ] = IsoValue(cellCornerPos);
}
// Tiangulate cell
Triangulate(cell, triangles, &nTriangles);
// Loop over triangles
for (int i = 0; i < nTriangles; ++i)
{
const Triangle &tri = triangles[ i ];
for (int j = 0; j < 3; ++j)
{
const D3DXVECTOR3 &vertexPos = tri.p[j];
// Allocate new vertex & index
indices[indexCount++] = vertexCount;
vertices[vertexCount++] = vertexPos;
}
}
}
Eliminating redundant iso function evaluations
The first and most disruptive issue concerning mesh generation time is the fact that most of the voxel grid cell's corner density values are evaluated a total of eight times, which is seven times too much for time-consuming computations such as in procedural content creation (in every layer of voxel cells, each corner point is shared by four cells, in addition, each corner point is shared by two layers, resulting in a total of 8 cells sharing the same corner point).

I.1: Grid, layers, cells and their shared corner points
The most simple solution of course would be to simply evaluate every corner point in advance, sampling the array of pre-computed iso values during mesh generation afterwards. The trouble with this solution is that the size of such an array would be proportional to the number of cells in every direction, easily reaching several gigabytes at decent step counts.
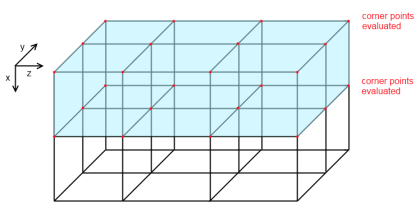
I.2: Pre-evaluation of top and bottom corner points (first layer)

I.3: Previous pre-evaluated bottom layer re-used as top layer
Fortunately, we can make the idea perfectly applicable by analysing the order in which the iso values actually have to be available. The key observation to be made here is that the grid cells are polygonised in layers, omitting the outer loop, we obtain the code for generating one yz-layer of triangle data. Pre-evaluating the iso values of one layer reduces the array size by an order of magnitude, making the storage of pre-evaluated corner points perfectly feasible. However, only working our way through the grid layer by layer, we ignore the fact that corner density values are shared in-between layers, leaving the number of evaluations of the same corner points at two times. Luckily, redundant evaluation can be totally elimated by storing two layers of pre-evaluated corners instead of just one layer, for each layer re-using the bottom pre-evaluated density values of the previous layer as top values, while filling the other layer array of pre-evaluated data with new bottom values. The two pre-evaluated value arrays are swapped each time the layer of cells to be triangluated changes.
static const D3DXVECTOR3 relativeCornerPositions[8] = {
{0,0,1}, {1,0,1}, {1,0,0}, {0,0,0},
{0,1,1}, {1,1,1}, {1,1,0}, {0,1,0} };D3DXVECTOR3 vertices[MAX_VERTICES];
unsigned int indices[MAX_INDICES];
int vertexCount = 0;
int indexCount = 0;
// Two layers of cached iso-values
static float cachedIsoValues[MAX_STEPS_Y * MAX_STEPS_Z * 2];
assert ( stepsY < MAX_STEPS_Y && stepsZ < MAX_STEPS_Z );
int iNextIsoCacheLayer = 0;
bool bFirstRun = true;
// Loop over grid cells
for (int x = 0; x < stepsX; ++x)
{
// Previous bottom (now top) layer, new bottom layer
int iIsoCacheLayers[2] = { (iNextIsoCacheLayer + 1) % 2, iNextIsoCacheLayer };
// Overwrite previous bottom layer next time
iNextIsoCacheLayer = iIsoCacheLayers[0];
// Fill both layers during the first run,
for (int r = 0; r < 1 + bFirstRun; ++r)
{
// New bottom layer first, old layer afterwards, iff first run
int iCacheBase = iIsoCacheLayers[1 - r] * stepsYZPP; // stepsYZPP = (stepsY + 1) * (stepsZ + 1)
int xpp = x + 1 - r;
// Loop over all corner points in this layer
for (int y = 0; y < stepsYPP; ++y) // stepsYPP = stepsY + 1
{
int iCacheBaseY = iCacheBase + y * stepsZPP;
for (int z = 0; z < stepsZPP; ++z) // stepsZPP = stepsZ + 1
{
D3DXVECTOR3 cellCornerPos = D3DXVECTOR3((float)xpp, (float)y, (float)z);
// Compute iso value once
cachedIsoValues[ iCacheBaseY + z ] = IsoValue( cellCornerPos );
}
}
}
for (int y = 0; y < stepsY; ++y)
for (int z = 0; z < stepsZ; ++z)
{
int nTriangles = 0;
Triangle triangles[5];
Cell cell;
// Loop over 8 cell corners
for (int i = 0; i < 8; ++i)
{
// Compute cell corner position
D3DXVECTOR3 &cellCornerPos = cell.p[ i ];
cellCornerPos = D3DXVECTOR3((float)x, (float)y, (float)z) + relativeCornerPositions[ i ];
// Sample iso value
int iCacheBase = iIsoCacheLayers[ (int)relativeCornerPositions[ i ].x ] * stepsYZPP;
int iCacheBaseY = iCacheBase + (int)cellCornerPos.y * stepsZPP;
grid.val[ i ] = cachedIsoValues[ iCacheBaseY + (int)cellCornerPos.z ];
assert( cell.val[ i ] == IsoValue(cellCornerPos) );
}
// Tiangulate cell
Triangulate(cell, triangles, &nTriangles);
// Loop over triangles
for (int i = 0; i < nTriangles; ++i)
{
const Triangle &tri = triangles[ i ];
for (int j = 0; j < 3; ++j)
{
const D3DXVECTOR3 &vertexPos = tri.p[j];
// Allocate new vertex & index
indices[indexCount++] = vertexCount;
vertices[vertexCount++] = vertexPos;
}
}
}
// First run is over
bFirstRun = false;
}
This rather straigt-forward solution reduced mesh generation time by a factor of 8 in one of our demos. Besides, it gave rise to a very similar idea of how to generate an optimized and perfectly indexed mesh from the output of the marching cubes algorithm nearly without sacrificing any valuable time at mesh generation to be described in the next section.
Generating a unified indexed triangle mesh
This optimization is going to be slightly more complicated, as some marching cubes theory will be involved, yet the solution is simple and elegant in the way that it works only based on the immediate output of the marching cubes algorithm, without modifying the actual algorithm itself, just like the elimination of redundant iso function evaluations described above. Again, it is an observation that lies at the heart of the optimized algorithm, the observation that any vertex output by the marching cubes algorithm sharing the same cell edge with another cell's vertex must be incident with that very vertex that has already been output before. Thus, the problem of finding redundant vertices is reduced to the problem of finding the right edge that a given vertex lies on.
As we are still working our way through the grid layer by layer, such sharing may only occur locally in-between neighboring layers, once again it is sufficient to store all vertices that have been generated on the bottom edges of the previous layer to be re-used by the next layer. We are also going to cache all vertices lying on edges that are entirely contained by one layer, as we of course also want to share these vertices in-between cells within one layer rather than just sharing in-between several layers.
There are two tricky parts when it comes to implementing the optimizations discussed, one being the buffer layout of the cache storing vertices generated on the cell edges of one layer, the other being the determination of the edge a given vertex lies on, including the location of the edge determined in the vertex cache buffer. For the center cache layer, the buffer layout is quite easy, the vertex entry of each edge simply corresponding to the cell corner it is standing on. Top and bottom cache layers are slightly trickier, as one y and one z edge are stored interleaved for each cell, resulting in an array size of two times the cell count (plus 1) per cache layer. All in all, this makes for a cache size of 5 times the cell count (plus 1). For each edge, the vertex entry stored is nothing but the index of the last vertex generated on that edge (which, based on the initial observation, means either one valid index or none).
To determine which edge a given vertex lies on, we simply compute the deviation of the vertex position from the edge coordinates of the corresponding cell on all three axis, simple comparison of the deviations yields which three edges are nearest, the closest edge (~0 deviation on TWO axis) of these three being the edge the vertex actually lies on.
static const D3DXVECTOR3 relativeCornerPositions[8] = {
{0,0,1}, {1,0,1}, {1,0,0}, {0,0,0},
{0,1,1}, {1,1,1}, {1,1,0}, {0,1,0} };D3DXVECTOR3 vertices[MAX_VERTICES];
unsigned int indices[MAX_INDICES];
int vertexCount = 0;
int indexCount = 0;
assert ( stepsY < MAX_STEPS_Y && stepsZ < MAX_STEPS_Z );
// Two layers of cached iso-values
static float cachedIsoValues[MAX_STEPS_Y * MAX_STEPS_Z * 2];
int iNextIsoCacheLayer = 0;
// Five layers of cached edge vertices
static unsigned int cachedEdgeVertices[MAX_STEPS_Y * MAX_STEPS_Z * 5];
// Clear
memset(cachedEdgeVertices, -1, sizeof(cachedEdgeVertices));
int iEdgeVertexCacheSmallLayerSize = stepsYZPP;
int iEdgeVertexCacheBigLayerSize = iEdgeVertexCacheSmallLayerSize * 2;
int iNextEdgeVertexCacheLayer = 0;
unsigned int iPrevEdgeVertexCacheLayerBaseValue = 0;
bool bFirstRun = true;
// Loop over grid cells
for (int x = 0; x < stepsX; ++x)
{
// Previous bottom (now top) layer, new bottom layer
int iIsoCacheLayers[2] = { (iNextIsoCacheLayer + 1) % 2, iNextIsoCacheLayer };
// Overwrite previous bottom layer next time
iNextIsoCacheLayer = iIsoCacheLayers[0];
// Fill both layers during the first run,
for (int r = 0; r < 1 + bFirstRun; ++r)
{
// New bottom layer first, old layer afterwards, iff first run
int iCacheBase = iIsoCacheLayers[1 - r] * stepsYZPP; // stepsYZPP = (stepsY + 1) * (stepsZ + 1)
int xpp = x + 1 - r;
// Loop over all corner points in this layer
for (int y = 0; y < stepsYPP; ++y) // stepsYPP = stepsY + 1
{
int iCacheBaseY = iCacheBase + y * stepsZPP;
for (int z = 0; z < stepsZPP; ++z) // stepsZPP = stepsZ + 1
{
D3DXVECTOR3 cellCornerPos = D3DXVECTOR3((float)xpp, (float)y, (float)z);
// Compute iso value once
cachedIsoValues[ iCacheBaseY + z ] = IsoValue( cellCornerPos );
}
}
}
// Previous bottom (now top) layer, new (bottom) layer
int iEdgeVertexOuterCacheLayers[2] = { (iNextEdgeVertexCacheLayer + 1) % 2, iNextEdgeVertexCacheLayer };
// Overwrite previous bottom layer next time
iNextEdgeVertexCacheLayer = iEdgeVertexOuterCacheLayers[0];
// Layer base pointers for top layer, center layer, bottom layer
int *pEdgeVertexCacheLayers[3] = {
cachedEdgeVertices + iEdgeVertexOuterCacheLayers[0] * iEdgeVertexCacheBigLayerSize,
cachedEdgeVertices + 2 * iEdgeVertexCacheBigLayerSize,
cachedEdgeVertices + iEdgeVertexOuterCacheLayers[1] * iEdgeVertexCacheBigLayerSize };
// Layer value bases (used to check validity)
int iEdgeVertexCacheLayerBaseValues[3] = {
iPrevEdgeVertexCacheLayerBaseValue,
vertexCount,
vertexCount };
// Current vertex count is base for next time
iPrevEdgeVertexCacheLayerBaseValue = iEdgeVertexCacheLayerBaseValues[2];
for (int y = 0; y < stepsY; ++y)
for (int z = 0; z < stepsZ; ++z)
{
int nTriangles = 0;
Triangle triangles[5];
Cell cell;
// Loop over 8 cell corners
for (int i = 0; i < 8; ++i)
{
// Compute cell corner position
D3DXVECTOR3 &cellCornerPos = cell.p[ i ];
cellCornerPos = D3DXVECTOR3((float)x, (float)y, (float)z) + relativeCornerPositions[ i ];
// Sample iso value
int iCacheBase = iIsoCacheLayers[ (int)relativeCornerPositions[ i ].x ] * stepsYZPP;
int iCacheBaseY = iCacheBase + (int)cellCornerPos.y * stepsZPP;
grid.val[ i ] = cachedIsoValues[ iCacheBaseY + (int)cellCornerPos.z ];
assert( cell.val[ i ] == IsoValue(cellCornerPos) );
}
// Tiangulate cell
Triangulate(cell, triangles, &nTriangles);
// Compute lower and upper cell bounds on all axis
float fCellXL = x, fCellXU = fCellXL + 1;
float fCellYL = y, fCellYU = fCellYL + 1;
float fCellZL = z, fCellZU = fCellZL + 1;
// Loop over triangles
for (int i = 0; i < nTriangles; ++i)
{
const Triangle &tri = triangles[ i ];
for (int j = 0; j < 3; ++j)
{
const D3DXVECTOR3 &pos = tri.p[j];
// Compute edge deviations from lower and upper bounds
float fEdgeXL = pos.x - fCellXL, fEdgeXU = fCellXU - pos.x;
float fEdgeYL = pos.y - fCellYL, fEdgeYU = fCellYU - pos.y;
float fEdgeZL = pos.z - fCellZL, fEdgeZU = fCellZU - pos.z;
// Compute three nearest edges
int iEdgeX = (fEdgeXL > fEdgeXU);
int iEdgeY = (fEdgeYL > fEdgeYU);
int iEdgeZ = (fEdgeZL > fEdgeZU);
// Store deviation from these nearest edges
float fEdgeXD = (iEdgeX) ? fEdgeXU : fEdgeXL;
float fEdgeYD = (iEdgeY) ? fEdgeYU : fEdgeYL;
float fEdgeZD = (iEdgeZ) ? fEdgeZU : fEdgeZL;
// Compute layer
int iEdgeLayer = (fEdgeXD > fEdgeYD && fEdgeXD > fEdgeZD)
? 1 // Center layer
: 2 * iEdgeX; // Top / bottom layer
// Get layer data
int *pLayerIndexValues = pEdgeVertexCacheLayers[iEdgeLayer];
int iLayerIndexBaseValue = iEdgeVertexCacheLayerBaseValues[iEdgeLayer];
int *pIndexValue = NULL;
// Center layer
if (iEdgeLayer == 1)
{
// Get index value (simple, edges standing on cell corners)
int iCacheBaseY = (y + iEdgeY) * stepsZPP;
int iCacheIndex = iCacheBaseY + (z + iEdgeZ);
pIndexValue = &pLayerIndexValues[iCacheIndex];
}
// Top / bottom layer
else
{
// Determine whether vertex on horizontal or vertical edge
int iOnY = (fEdgeYD > fEdgeZD);
int iEdgeZY = (iOnY) ? iEdgeZ : iEdgeY;
// Get index value (interleaved, first y then z edge for each cell)
int iCacheBaseY = ( (y + (1 - iOnY) * iEdgeZY) * 2 + iOnY ) * stepsZPP;
int iCacheIndex = iCacheBaseY + ( z + iOnY * iEdgeZY );
pIndexValue = &pLayerIndexValues[iCacheIndex];
}
assert ( pIndexValue != NULL );
// Get and check edge vertex index
int &indexValue = *pIndexValue;
bool bIndexValid = (indexValue >= iLayerIndexBaseValue);
// Only generate new vertices if edge vertex index invalid
if(!bIndexValid)
{
// Set new valid index
indexValue = vertexCount;
// Allocate new vertex
vertices[vertexCount++] = tri.p[j];
}
// Allocate new index
indices[indexCount++] = indexValue;
}
}
}
// First run is over
bFirstRun = false;
}
It would also be possible to move the caching of generated vertices right into the marching cubes triangluation function itself, eliminating both the need for edge determination from a given vertex position and re-interpolation of vertices already generated by previous cells, further reducing mesh generation time. The same buffer layout should be applicable, assuming that triangulation calls still occur layer by layer.
Results
The described optimizations of a naive marching cube algorithm helped us reduce both mesh generation time and the number of vertices output by the algorithm by a factor of eight, which is about as optimal as it can get considering the sharing relations in-between marching cubes grid cells.